


Welcome back folks, to another exciting ride with me. This time, I'll be walking you through my thought process on the Data Cleaning Challenge.
The dataset to be used for this cleaning challenge is the FIFA21 dataset containing details of 18979 players. Before I go into the main issue for today, let's discuss data cleaning and its importance in analysis.
Just as no one likes to eat with dirty plates, so also, no one likes to work with unclean data.
Clean data is important for the following reasons:
Removal of errors that could lead to misleading or incorrect insights.
Fewer errors mean more accurate decisions and happier clients.
Data is easier to work with for future analysis.
Working with clean data saves time and money.
It also increases productivity.
You can add yours...
Now we know why data cleaning is necessary. Let's dive right into it.
Get your brooms and mops ready because this is one messy data.

I'll be using Python for this cleaning process. First, load the dataset using pandas and view. A datatype warning is thrown as shown below.
To bypass this warning, include the parameter low_memory = False .
Understanding the Data
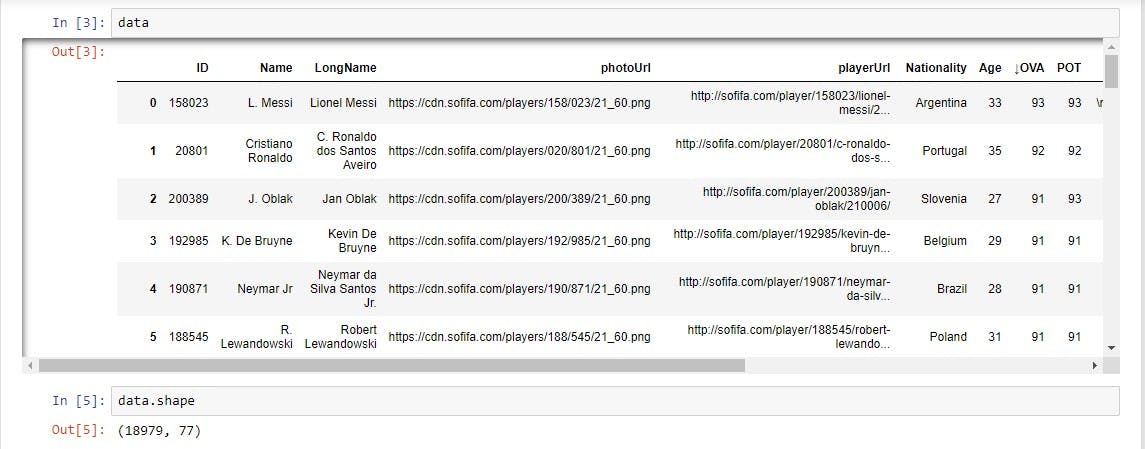
The data contains 77 variables describing 18979 FIFA players. Most of the variables are common knowledge such as Player ID, Name, Nationality, Age, Club, Positions, etc. Over the course of this challenge, i will explain some variables which may seem foreign to readers who are not into football.
Next, checking for tidiness.
Tidy data possesses the following characteristics:
Each variable is a column.
Each observation is a row.
Each type of observational unit forms a table.
Visual assessment shows that the data possesses the three characteristics and can be described as tidy.
Checking Datatype
Notice that the ID column is an identifier and unique for all players. It may be numerical, however quantitative operations shouldn't be carried out on the column so it should be treated as a string. This requires changing the datatype to string(object).
data['ID'].astype(str)
Other columns are in the right datatypes. Moving on, check for quality issues following the six dimenions of Data Quality.
- Completeness: This involves checking for missing values, duplicate rows.
data.info() shows that there are no missing values. The two rows where the non-null values are less than 18979 are the Loan Date End and Hits. This is not relevant enough to re der the data incomplete since not all players may be on loan and not all players may have made physical contact with an opposing player(i.e. hits).
We've done quite some work today trying to understand the data and checking for datatypes and completeness of the data. Let's lay down our tools for the day. We'll continue cleaning tomorrow.
See you...